
Natural Language Autoencoders Produce Unsupervised Explanations of LLM Activations
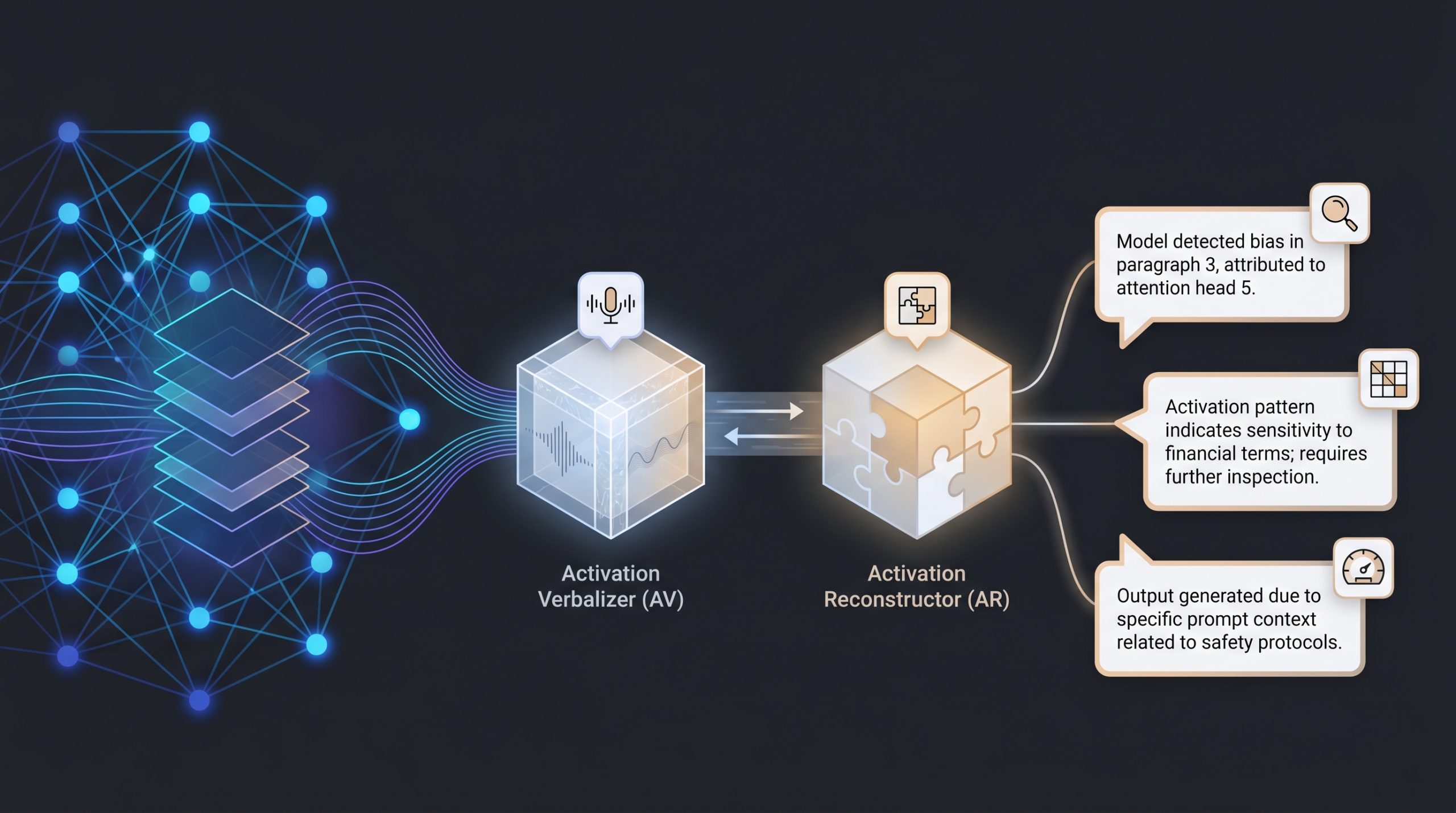
We introduce Natural Language Autoencoders (NLAs), an unsupervised method for generating natural language explanations of LLM activations. An NLA consists of two LLM modules: an activation verbalizer (AV) that maps an activation to a text description, and an activation reconstructor (AR) that maps the description back to an activation. We jointly train the AV and AR with reinforcement learning to reconstruct residual stream activations.
Although the system is optimized for activation reconstruction, the resulting NLA explanations read as plausible interpretations of model internals and, according to quantitative evaluations, become more informative over training.
We apply NLAs to model auditing. During a pre-deployment audit of Claude Opus 4.6, NLAs helped diagnose safety-relevant behaviors and surfaced unverbalized evaluation awareness—cases where Claude appeared to believe it was being evaluated without explicitly stating so. We present these audit findings as case studies and corroborate them using independent methods.
On an automated auditing benchmark requiring end-to-end investigation of an intentionally misaligned model, agents equipped with NLAs outperform baselines and can succeed even without access to the misaligned model’s training data.
NLAs provide a convenient interpretability interface through expressive natural language explanations that humans can directly read. To support further research, we release training code and trained NLAs for popular open models.





