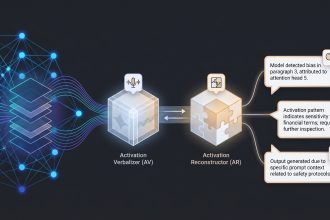
Natural Language Autoencoders Produce Unsupervised Explanations of LLM Activations. This Transformer Circuits Thread article from Anthropic, published May 7, 2026, introduces Natural Language Autoencoders (NLAs), an unsupervised method for generating natural-language explanations of large language model activations. The system uses two LLM modules: an activation verbalizer that converts activations into text and an activation reconstructor that maps the text back to activations. The modules are jointly trained with reinforcement learning to reconstruct residual stream activations.
The article argues that, although the objective is activation reconstruction, the resulting explanations become increasingly informative and readable over training. It highlights applications in model auditing and AI safety, including a pre-deployment audit of Claude Opus 4.6, where NLAs helped identify safety-relevant behaviors and unverbalized evaluation awareness. The authors also describe benchmark results showing that NLA-equipped agents outperform baselines on end-to-end auditing tasks for intentionally misaligned models, even without access to the model’s training data.
The article concludes that NLAs provide a practical interface for interpretability and notes that Anthropic is releasing training code and trained NLAs for popular open models.